Which Of The Following Is True About Database Rows
Holbox
Mar 29, 2025 · 6 min read
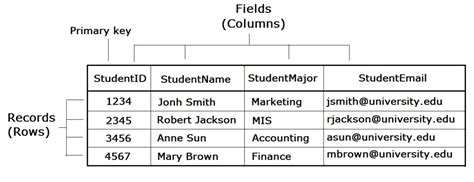
Table of Contents
- Which Of The Following Is True About Database Rows
- Table of Contents
- Decoding Database Rows: A Comprehensive Guide
- What is a Database Row?
- Common Misconceptions About Database Rows
- Working with Database Rows: Common Operations
- The Importance of Primary Keys in Defining Database Rows
- Database Row Optimization Techniques
- Advanced Concepts: Row Versioning and Transactions
- Database Rows and Different Database Models
- Conclusion: Mastering Database Rows for Effective Data Management
- Latest Posts
- Latest Posts
- Related Post
Decoding Database Rows: A Comprehensive Guide
Understanding database rows is fundamental to working effectively with databases. This in-depth guide explores the nature of database rows, addressing common misconceptions and providing a comprehensive overview of their characteristics, functionalities, and importance within the broader context of database management. We'll delve into various aspects, clarifying what's true and debunking myths surrounding these crucial elements of relational databases.
What is a Database Row?
A database row, also known as a record, represents a single, complete unit of data within a database table. Imagine a table in a spreadsheet; each row contains information about a single entity. In a database context, this entity could be a customer, a product, a transaction, or any other data element you want to store and manage.
Each row is uniquely identifiable within its table, typically through a primary key, a unique identifier that prevents duplication and ensures data integrity. Rows are composed of multiple columns or fields, each representing a specific attribute of the entity. For example, in a "Customers" table, a single row might contain information like CustomerID, Name, Address, and Phone Number. Each of these pieces of information resides in a separate column.
Key Characteristics of Database Rows:
- Uniqueness (through Primary Key): Each row is distinct and identifiable by its primary key. This prevents duplicate entries and ensures data consistency.
- Ordered Structure: Rows are typically stored in a defined order within the table, although this order might not be explicitly enforced and could change based on various database operations.
- Data Integrity: Rows contribute to the overall data integrity of the database by ensuring each record is complete and consistent with the table's schema.
- Relationship to other Rows (Foreign Keys): Rows can be related to rows in other tables through foreign keys, creating connections and allowing for efficient data retrieval and manipulation. This forms the foundation of relational database management.
- Dynamic Nature: Rows can be added, updated, or deleted throughout the database's lifecycle. Database management systems (DBMS) are designed to handle these changes efficiently and maintain data integrity.
Common Misconceptions About Database Rows
Several misconceptions surround database rows. Let's address some of the most common ones:
1. Rows Always Maintain Insertion Order: While many database systems appear to preserve the insertion order of rows, it's crucial to understand that this is not guaranteed. The physical storage of rows might be optimized for retrieval speed or other factors, meaning the order in which rows appear might not reflect the sequence in which they were inserted. Queries should never rely on insertion order for data retrieval.
2. Row Order Determines Data Importance: The order of rows within a table does not inherently indicate any level of importance or priority. Any apparent ordering is usually for display purposes and should not be interpreted as a ranking mechanism within the data.
3. All Columns in a Row Must Be Populated: While it's best practice to have complete and accurate data, not all columns within a row need to be filled. Some columns might allow for NULL values, representing the absence of data for that specific attribute.
4. Row Size is Fixed: The size of a row isn't inherently fixed. While the schema defines the data types of each column, the actual size of a row can vary depending on the data stored within it. For instance, a text column can store varying lengths of text, affecting the overall row size.
Working with Database Rows: Common Operations
Database operations heavily involve manipulating rows. Here are some fundamental operations:
-
SELECT: Retrieves specific rows based on defined criteria. This is one of the most common database operations, allowing users to query and retrieve relevant data.
SELECT * FROM Customers WHERE Country = 'USA';is a typical example. -
INSERT: Adds new rows to a table. This operation introduces new data into the database.
INSERT INTO Customers (Name, Address, Country) VALUES ('John Doe', '123 Main St', 'USA');shows a basic insert operation. -
UPDATE: Modifies existing rows. This operation updates specific columns in existing rows.
UPDATE Customers SET Address = '456 Oak Ave' WHERE CustomerID = 1;is an example of updating a specific customer's address. -
DELETE: Removes rows from a table. This operation permanently removes data from the database.
DELETE FROM Customers WHERE CustomerID = 1;deletes a specific customer record.
The Importance of Primary Keys in Defining Database Rows
Primary keys are paramount to the integrity and efficiency of database operations. A primary key serves the following critical functions:
-
Unique Identification: Ensures each row has a unique identifier within the table, preventing duplicate records and maintaining data consistency.
-
Data Integrity Enforcement: The DBMS enforces constraints to prevent insertion or updates that violate the primary key uniqueness constraint.
-
Efficient Data Retrieval: Primary keys significantly optimize data retrieval. Database systems use indexes to quickly locate rows based on their primary key values.
-
Relationships between Tables: Primary keys act as foreign keys in other tables, establishing relationships between different entities and enabling efficient data querying across multiple tables.
Database Row Optimization Techniques
Optimizing database rows and related structures is crucial for database performance. Here are some key optimization techniques:
-
Appropriate Data Types: Choosing the correct data type for each column minimizes storage space and improves query performance. Using smaller data types when appropriate reduces overall row size, leading to faster data retrieval.
-
Indexing: Creating indexes on frequently queried columns dramatically improves the speed of data retrieval. Indexes function similarly to the index of a book, allowing the database system to quickly locate specific rows based on specified criteria.
-
Normalization: Normalization involves organizing data to reduce redundancy and improve data integrity. It ensures that data is stored in a structured way, minimizing data duplication and improving overall database performance.
-
Data Compression: Employing data compression techniques can reduce the storage space required for database rows, leading to improved performance, especially when dealing with large volumes of data.
Advanced Concepts: Row Versioning and Transactions
Advanced database features further enhance the management and control of database rows:
-
Row Versioning: Some database systems support row versioning, allowing users to track changes to data over time. This is crucial for auditing and data recovery purposes.
-
Transactions: Transactions guarantee data integrity by grouping multiple database operations into a single unit of work. If any operation within the transaction fails, the entire transaction is rolled back, ensuring the database remains in a consistent state. This is fundamental to maintaining data reliability, especially in multi-user environments.
Database Rows and Different Database Models
While we've primarily focused on relational databases, the concept of a row, representing a single unit of data, extends to other database models, although the specifics might vary.
-
NoSQL Databases: NoSQL databases, like MongoDB, often utilize document-based models. While they don't have the strict row-column structure of relational databases, the concept of a document (analogous to a row) holds the data for a single entity.
-
Graph Databases: Graph databases, such as Neo4j, represent data as nodes and relationships. While not explicitly rows, individual nodes can be seen as containing data analogous to rows in a relational database.
Conclusion: Mastering Database Rows for Effective Data Management
Understanding database rows is crucial for anyone working with databases. This guide has provided a comprehensive exploration of database rows, addressing common misconceptions and detailing their functionalities and importance. By applying the concepts and techniques described here, you can build more efficient and reliable database systems, ensuring data integrity and optimal performance. Remember, efficient data management hinges on a thorough understanding of these fundamental database building blocks. Continuously learning and implementing best practices around data management is paramount to creating robust and scalable applications.
Latest Posts
Latest Posts
-
Selections Made With Replacement Are Considered To Be
Apr 02, 2025
-
Which Of The Following Scenarios Involves The Administration Of Als
Apr 02, 2025
-
Draw The Major Product Of The Reaction Sequence Omit Byproducts
Apr 02, 2025
-
An It Is Consulted About Setting
Apr 02, 2025
-
A Pizza Parlor Offers 8 Different Toppings
Apr 02, 2025
Related Post
Thank you for visiting our website which covers about Which Of The Following Is True About Database Rows . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
