In Machine Learning When A Data Model Performs Exceptionally Well
Holbox
Mar 10, 2025 · 6 min read
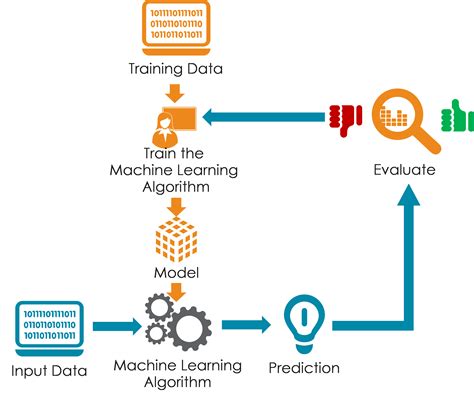
Table of Contents
When Your Machine Learning Model Performs Exceptionally Well: Understanding Overfitting, Generalization, and the Path to Robust Performance
Machine learning models are trained to learn patterns from data, enabling them to make predictions or decisions on new, unseen data. When a model performs exceptionally well during training, it's tempting to celebrate. However, this seemingly stellar performance can be deceptive. A model's exceptional performance on training data doesn't automatically translate to real-world success. Understanding why a model excels, and whether that success is genuine or an illusion, is crucial for building robust and reliable machine learning systems. This article delves into the complexities of exceptional model performance, exploring the pitfalls of overfitting, the importance of generalization, and strategies for achieving truly impressive and reliable results.
The Allure of Exceptional Training Performance
An exceptionally well-performing model, boasting near-perfect accuracy or incredibly low error rates on the training dataset, is undeniably attractive. It seems to indicate that the model has perfectly captured the underlying patterns in the data. However, this perception can be misleading. The model might be merely memorizing the training data instead of truly understanding the underlying patterns. This phenomenon is known as overfitting.
Understanding Overfitting: The Enemy of Generalization
Overfitting occurs when a model learns the training data too well, including the noise and irrelevant details. It essentially memorizes the training examples, becoming highly specialized to that specific dataset. Consequently, its performance on unseen data – the real test of its efficacy – dramatically deteriorates. Imagine training a model to identify cats based solely on pictures of a specific breed of Persian cat with a particular coloration. This model will likely perform exceptionally well on similar Persian cats but fail miserably when presented with Siamese cats, Maine Coons, or even slightly different-looking Persians.
Causes of Overfitting:
- Model Complexity: Highly complex models with numerous parameters (e.g., deep neural networks with many layers and neurons) have a greater capacity to memorize the training data, increasing the risk of overfitting.
- Insufficient Data: When the training dataset is small, the model doesn't have enough examples to learn generalizable patterns. It's forced to rely on specific instances, leading to overfitting.
- Noisy Data: Data containing errors or irrelevant information can confuse the model, leading it to learn spurious correlations rather than true underlying patterns. The model might overfit to the noise instead of the signal.
- Poor Feature Engineering: If the features used to train the model are not relevant or informative, the model might struggle to learn meaningful patterns and resort to memorizing the training data.
Recognizing the Signs of Overfitting: A Diagnostic Approach
Several indicators can signal overfitting:
- Significant Discrepancy between Training and Validation/Test Set Performance: A large difference in accuracy or error rates between the training set and validation/test sets is a strong indicator of overfitting. The model performs exceptionally well on the training data but poorly on unseen data.
- High Variance: The model's performance fluctuates significantly across different training sets or subsets of the data.
- Complex Model Structure: A model that's unnecessarily complex (more parameters than necessary) often suggests overfitting.
- Visual Inspection (for simpler models): For models like decision trees, visualizing the tree structure can reveal overly complex branches that suggest overfitting.
The Importance of Generalization: The Key to Real-World Success
Generalization is the ability of a model to accurately predict or classify unseen data. It's the ultimate goal of machine learning. A model that generalizes well performs consistently across different datasets and situations, demonstrating its true understanding of the underlying patterns.
Strategies for Improving Generalization:
- Data Augmentation: Increasing the size and diversity of the training dataset by creating modified versions of existing data points (e.g., rotating, cropping, or adding noise to images).
- Regularization Techniques: Methods like L1 and L2 regularization penalize overly complex models, discouraging overfitting by constraining the magnitude of model parameters. Dropout, a technique commonly used in neural networks, randomly ignores neurons during training, further preventing overfitting.
- Cross-Validation: This technique divides the dataset into multiple folds, training the model on some folds and validating it on others. This helps estimate the model's performance on unseen data more accurately.
- Early Stopping: Monitoring the model's performance on a validation set during training and stopping the training process when the validation performance starts to degrade. This prevents the model from continuing to overfit.
- Feature Selection/Engineering: Carefully selecting or creating relevant features can significantly improve model generalization. Removing irrelevant or redundant features can reduce noise and improve the model's ability to learn meaningful patterns.
- Ensemble Methods: Combining multiple models (e.g., bagging, boosting) often leads to improved generalization and robustness.
- Model Selection: Choosing a model appropriate for the task and data complexity. A simpler model might be sufficient for less complex tasks, reducing the risk of overfitting.
When Exceptional Performance is Genuine: Signs of a Well-Trained Model
While overfitting is a common pitfall, exceptional performance can indeed be genuine. Several signs indicate a model has truly learned the underlying patterns:
- Consistent Performance across Multiple Datasets: The model achieves excellent performance not just on the training data but also on various independent test sets representing different scenarios or distributions.
- Robustness to Noise and Variations: The model's performance remains stable even when presented with noisy or slightly altered data.
- Interpretability (when applicable): For some models, the decision-making process can be examined. A well-trained model's decisions should be logical and consistent with domain expertise.
- Strong Theoretical Foundation: The model's architecture and training methods align with established machine learning principles and best practices.
- Meaningful Feature Importance: The features that the model deems most important align with domain knowledge and intuition.
The Path to Robust and Reliable Machine Learning
Building a machine learning model that delivers exceptional and reliable performance requires a systematic approach:
- Data Preparation: Thoroughly clean, pre-process, and explore the data to understand its characteristics and potential biases. Address missing values, outliers, and inconsistencies.
- Feature Engineering: Carefully select and engineer features that capture relevant information while minimizing noise.
- Model Selection: Choose an appropriate model architecture based on the nature of the problem and the data.
- Hyperparameter Tuning: Optimize the model's hyperparameters (settings that control the training process) to achieve optimal performance.
- Regularization and Generalization Techniques: Employ strategies to prevent overfitting and improve generalization, as discussed above.
- Rigorous Evaluation: Use appropriate evaluation metrics and cross-validation techniques to assess the model's performance on unseen data.
- Iterative Refinement: Machine learning is an iterative process. Continuously evaluate and refine the model based on its performance, adjusting the data, features, or model architecture as needed.
- Monitoring and Maintenance: Even after deployment, monitor the model's performance in the real world and retrain it periodically to adapt to changes in the data distribution or environment.
Conclusion: Beyond the Numbers
Exceptional performance in machine learning is not solely defined by impressive numbers on a training set. True success lies in building models that generalize well, providing reliable and consistent performance on unseen data. By understanding the pitfalls of overfitting, prioritizing generalization, and employing a robust development process, you can build machine learning models that deliver truly exceptional results, transforming data into actionable insights and driving real-world impact. The journey is about more than just achieving high accuracy; it's about building trust, reliability, and ultimately, solving real-world problems.
Latest Posts
Latest Posts
-
Which Is Not A Limitation Of Using Closed Source Llms
Mar 10, 2025
-
Employees Working For A Licensed Establishment
Mar 10, 2025
-
Predict The Major Product Of The Following Reactions
Mar 10, 2025
-
Ap Classroom Unit 8 Progress Check Mcq Answers
Mar 10, 2025
-
Calculate The Node Voltages In The Circuit Shown Below
Mar 10, 2025
Related Post
Thank you for visiting our website which covers about In Machine Learning When A Data Model Performs Exceptionally Well . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
