How Many Variables Are In The Data Set
Holbox
Mar 29, 2025 · 5 min read
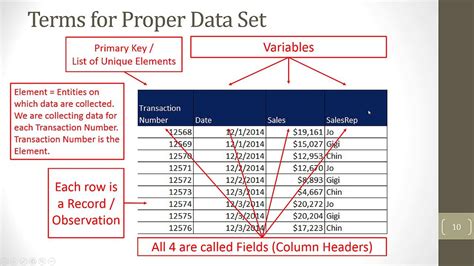
Table of Contents
- How Many Variables Are In The Data Set
- Table of Contents
- How Many Variables Are in Your Dataset? A Comprehensive Guide
- Defining Variables in a Dataset
- Types of Variables
- Methods for Determining the Number of Variables
- Spreadsheet Software (Excel, Google Sheets)
- Statistical Software (R, Python, SPSS)
- Database Systems (SQL)
- Implications of the Number of Variables
- Data Complexity
- Computational Resources
- Overfitting
- Curse of Dimensionality
- Interpretability
- Handling a Large Number of Variables
- Feature Selection
- Dimensionality Reduction
- Feature Engineering
- Conclusion
- Latest Posts
- Latest Posts
- Related Post
How Many Variables Are in Your Dataset? A Comprehensive Guide
Understanding the number of variables in your dataset is fundamental to any data analysis project. This seemingly simple question actually touches upon several crucial aspects of data science, from initial data exploration and cleaning to choosing appropriate analytical methods and interpreting results. This comprehensive guide will delve into the complexities behind counting variables, exploring different variable types, and highlighting the implications of variable count on your analysis.
Defining Variables in a Dataset
Before we jump into counting variables, let's clarify what we mean by a "variable." In the context of data analysis, a variable is a characteristic or attribute that can be measured or observed and that can take on different values. Think of it as a column in a spreadsheet or a feature in your dataset. These values can be numerical (like age or income) or categorical (like gender or color).
Types of Variables
Understanding the types of variables present in your dataset is critical. Different variable types require different analytical approaches. The main types include:
-
Numerical Variables: These represent quantities and can be further categorized as:
- Continuous Variables: Can take on any value within a range (e.g., height, weight, temperature).
- Discrete Variables: Can only take on specific, separate values (e.g., number of children, number of cars owned).
-
Categorical Variables: These represent categories or groups and can be further categorized as:
- Nominal Variables: Categories have no inherent order (e.g., color, gender).
- Ordinal Variables: Categories have a meaningful order (e.g., education level – high school, bachelor's, master's).
Methods for Determining the Number of Variables
The approach to counting variables depends on the format of your data.
Spreadsheet Software (Excel, Google Sheets)
In spreadsheet software, counting variables is straightforward:
- Identify Columns: Each column typically represents a single variable.
- Count Columns: Simply count the number of columns in your spreadsheet. This directly gives you the number of variables.
This method is suitable for smaller datasets where the data structure is clearly defined.
Statistical Software (R, Python, SPSS)
Statistical software packages offer more sophisticated methods, especially helpful with larger or more complex datasets.
-
Using Data Exploration Functions: Most packages have built-in functions to examine the structure of your data. For example:
- R:
str(your_data)provides a summary of your data, including the number of variables and their types. - Python (Pandas):
your_data.info()provides similar information, showing data types, non-null counts, and memory usage. - SPSS: The Variable View in the Data Editor clearly lists all variables with their properties.
- R:
-
Directly Accessing Dimensions: You can often directly access the dimensions of your data structure. In Python (Pandas),
your_data.shapereturns a tuple, where the first element is the number of rows and the second is the number of columns (variables).
These methods are more robust, especially when dealing with complex data structures, missing values, or nested data.
Database Systems (SQL)
If your data resides in a database, SQL queries are essential:
INFORMATION_SCHEMA: Databases like MySQL and PostgreSQL offerINFORMATION_SCHEMAwhich contains metadata about your database. You can query this schema to find the number of columns in a specific table, essentially the number of variables. An example query might look like:
SELECT COUNT(*)
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = 'your_table_name';
This approach is efficient for large datasets stored in databases, offering a scalable and standardized way to get the variable count.
Implications of the Number of Variables
The number of variables significantly impacts your analysis:
Data Complexity
A large number of variables can lead to increased data complexity. This complexity demands more sophisticated techniques for analysis and interpretation, potentially requiring dimensionality reduction methods (like Principal Component Analysis or t-SNE) to manage the high dimensionality.
Computational Resources
Analyzing datasets with many variables requires substantial computational resources. Both memory and processing power can become limiting factors as the number of variables grows. Choosing efficient algorithms and appropriate software becomes critical.
Overfitting
In predictive modeling, a high number of variables can lead to overfitting, where the model performs well on the training data but poorly on unseen data. Techniques like regularization or feature selection are essential to mitigate overfitting.
Curse of Dimensionality
The "curse of dimensionality" refers to the phenomenon where the volume of data needed to reliably estimate a function increases exponentially as the dimensionality (number of variables) increases. This makes it increasingly challenging to draw meaningful conclusions from high-dimensional data.
Interpretability
While more variables might seem to provide a richer understanding, too many can reduce the interpretability of the results. Understanding the relationships between numerous variables can become exceedingly difficult. Careful feature selection and visualization are necessary to manage this.
Handling a Large Number of Variables
If you find yourself with a very large number of variables, several strategies can help:
Feature Selection
This involves selecting a subset of variables that are most relevant to your analysis. Techniques include:
- Filter methods: Ranking variables based on statistical measures (e.g., correlation, chi-squared test).
- Wrapper methods: Evaluating subsets of variables using a predictive model.
- Embedded methods: Integrating feature selection into the model-building process (e.g., LASSO regression).
Dimensionality Reduction
These techniques transform the data into a lower-dimensional space while preserving essential information:
- Principal Component Analysis (PCA): Creates new, uncorrelated variables that capture the most variance in the data.
- t-distributed Stochastic Neighbor Embedding (t-SNE): Visualizes high-dimensional data in a lower-dimensional space, preserving local neighborhood structure.
Feature Engineering
Creating new variables from existing ones can improve model performance and interpretability. This involves combining or transforming variables to capture more meaningful information.
Conclusion
Determining the number of variables in your dataset is a critical first step in any data analysis project. Understanding the types of variables, utilizing appropriate methods for counting them across different data formats, and acknowledging the implications of variable count on your analysis are all vital for success. When dealing with large numbers of variables, strategies like feature selection, dimensionality reduction, and feature engineering are invaluable in managing complexity, improving model performance, and enhancing the interpretability of your results. Remember, the goal is not just to count the variables, but to effectively utilize them to gain valuable insights from your data. A thorough understanding of your data and its characteristics is paramount to effective data analysis.
Latest Posts
Latest Posts
-
The Different Dimensions Within Leadership Ethics Influence One Another
Apr 01, 2025
-
What Does Being A Manager Offer To An Employee
Apr 01, 2025
-
The Function Requires That Management Evaluate Operations Against Some Norm
Apr 01, 2025
-
Select The Two Primary Characteristics That Define Advertising
Apr 01, 2025
-
Trade Can Make Everyone Better Off Because It
Apr 01, 2025
Related Post
Thank you for visiting our website which covers about How Many Variables Are In The Data Set . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
