Fill In The Information Missing From This Table
Holbox
Mar 14, 2025 · 6 min read
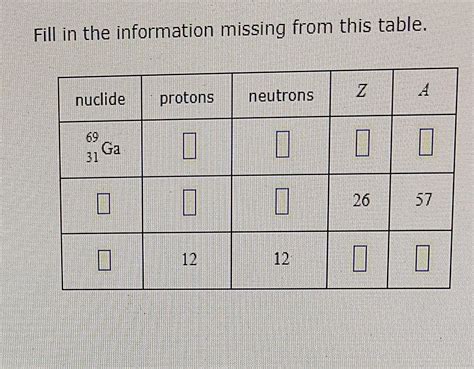
Table of Contents
Filling in the Missing Information: A Comprehensive Guide to Data Imputation
Data is the lifeblood of any analysis, but incomplete datasets are a common hurdle. Missing data can significantly bias results and undermine the validity of your conclusions. This comprehensive guide dives deep into the world of data imputation, exploring various techniques and best practices to fill in those missing information gaps and unlock the full potential of your dataset. We'll cover everything from understanding the nature of missing data to selecting the most appropriate imputation method for your specific scenario.
Understanding the "Why" Behind Missing Data
Before jumping into imputation techniques, it's crucial to understand why data is missing. This understanding guides the choice of imputation method and helps prevent introducing further bias. There are three main types of missing data mechanisms:
1. Missing Completely at Random (MCAR)
Data is MCAR if the probability of missingness is completely unrelated to any observed or unobserved variables. For instance, if a survey respondent randomly skips a question, this might be considered MCAR. This is the ideal scenario for imputation, as it minimizes bias.
2. Missing at Random (MAR)
Data is MAR if the probability of missingness depends on other observed variables but not on the missing values themselves. For example, if men are less likely to answer a question about their weight, this is MAR because the missingness depends on gender (an observed variable).
3. Missing Not at Random (MNAR)
Data is MNAR if the probability of missingness depends on the missing values themselves. This is the most challenging scenario. Imagine people with high incomes are less likely to report their income; the missingness is related to the missing income value itself. Imputation in this case is tricky and might introduce significant bias.
Identifying the missing data mechanism is crucial. While often impossible to definitively determine, careful consideration of the data collection process and subject matter expertise can provide valuable insights.
Exploring Data Imputation Techniques
Numerous techniques exist for handling missing data, each with its strengths and weaknesses. Choosing the right method depends on the type of data (categorical, numerical), the missing data mechanism, and the characteristics of the dataset.
1. Deletion Methods: Simple, but Potentially Problematic
The simplest approaches involve deleting data points with missing values. However, this often leads to a significant reduction in sample size, potentially losing valuable information and biasing the results.
-
Listwise Deletion (Complete Case Analysis): Entire rows with any missing values are removed. This is straightforward but leads to substantial information loss, especially with many variables or a high percentage of missing data.
-
Pairwise Deletion: Only cases with missing values for a specific variable are omitted when that variable is used in an analysis. This preserves more data than listwise deletion but can lead to inconsistencies and difficulties in interpretation.
Deletion methods are generally avoided unless the amount of missing data is minimal and the data is MCAR.
2. Single Imputation Techniques: Filling the Gaps
These methods replace missing values with a single estimated value. They are easier to implement than multiple imputation but can underestimate uncertainty.
-
Mean/Median/Mode Imputation: This involves replacing missing values with the mean (for numerical data), median (for skewed numerical data), or mode (for categorical data) of the observed values. Simple but can distort the distribution and reduce variability.
-
Regression Imputation: Missing values are predicted using a regression model based on observed values of other variables. More sophisticated than mean/median/mode imputation, but still prone to underestimating uncertainty and potentially creating unrealistic values.
-
K-Nearest Neighbors (KNN) Imputation: Missing values are estimated based on the values of the 'k' nearest neighbors in the data. Considers the relationships between variables but can be computationally intensive for large datasets.
-
Stochastic Regression Imputation: Adds randomness to regression imputation, acknowledging the uncertainty in the prediction. This helps create a more realistic representation of the data compared to standard regression imputation.
3. Multiple Imputation Techniques: Accounting for Uncertainty
Multiple imputation acknowledges the uncertainty inherent in estimating missing values. Instead of a single imputed value, multiple plausible imputed datasets are created, each reflecting different possible completions of the missing data. The results from analyzing these datasets are then combined to obtain a more robust estimate, considering the variability introduced by the missing data.
- Multiple Imputation by Chained Equations (MICE): A widely used iterative approach that models each variable with missing values as a function of other variables, repeatedly imputing missing values until convergence. This accounts for correlations between variables and provides a more realistic estimate of uncertainty.
Choosing the Right Imputation Method
The optimal imputation method depends on several factors:
-
Type of missing data mechanism: MCAR allows for a wider range of techniques; MNAR requires careful consideration and potentially more advanced methods.
-
Type of data: Numerical and categorical data require different imputation approaches.
-
Amount of missing data: Large amounts of missing data might necessitate more sophisticated methods like multiple imputation.
-
Dataset size: Computational complexity varies across methods. KNN imputation can be computationally intensive for large datasets.
-
Research question: The choice of imputation method should align with the goals of the analysis.
Consider starting with simpler methods if the amount of missing data is small and you suspect MCAR. For larger amounts of missing data or when MAR or MNAR is suspected, multiple imputation is generally recommended.
Evaluating Imputation Performance
After imputing missing values, it's essential to assess the performance of the chosen method. This involves evaluating how well the imputed data reflects the true underlying data distribution and avoids introducing bias. Techniques include:
-
Visual inspection: Examine histograms, scatter plots, and other visualizations to compare the distributions of imputed and observed data.
-
Statistical comparisons: Assess whether the imputed values are consistent with the observed values using statistical tests (e.g., t-tests, chi-square tests).
-
Sensitivity analysis: Compare the results of analyses using different imputation methods to assess the robustness of the findings.
Remember, no imputation method is perfect. The goal is to minimize bias and uncertainty while preserving the integrity of the data analysis.
Practical Considerations and Best Practices
-
Document your imputation strategy: Clearly detail the methods used, rationale for choices, and any limitations.
-
Use appropriate software: Many statistical software packages (R, SAS, SPSS, Python with libraries like scikit-learn and impute) provide functions for data imputation.
-
Validate your imputed data: Thoroughly assess the imputed data for accuracy and consistency.
-
Consider alternative analytical approaches: If imputation introduces significant uncertainty, explore alternative analysis methods that are less sensitive to missing data, such as multiple imputation or robust statistical techniques.
Conclusion: Unlocking the Power of Incomplete Data
Missing data is a prevalent challenge in data analysis. However, by understanding the different types of missing data mechanisms and utilizing appropriate imputation techniques, you can effectively fill in the gaps and extract meaningful insights from incomplete datasets. Remember to carefully consider the strengths and weaknesses of each method, document your approach, and validate your results. By following these best practices, you can move beyond the limitations of missing information and harness the full potential of your data. This leads to more robust and reliable conclusions, enhancing the value and impact of your research or analysis. Approaching missing data with a strategic and well-informed approach ensures that the information you do have is used to its maximum potential, thereby generating more reliable findings. Remember that choosing the right method and being transparent about the approach taken are critical steps to maintaining the integrity and reliability of your analysis.
Latest Posts
Latest Posts
-
A Potential Legal Claim Is Recorded
Mar 14, 2025
-
What Are Three Responsibilities Of The Transport Layer Choose Three
Mar 14, 2025
-
Question Pine Draw The Skeletal Structure Of The Alkane Given
Mar 14, 2025
-
Match The Term And The Definition
Mar 14, 2025
-
Glimpse Is To Stare As Sprinkle Is To
Mar 14, 2025
Related Post
Thank you for visiting our website which covers about Fill In The Information Missing From This Table . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
