Based On The Values In Cells B77:b81
Holbox
Mar 14, 2025 · 7 min read
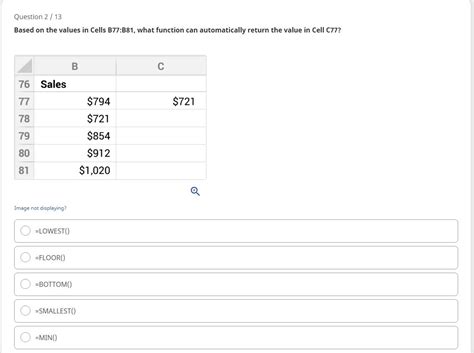
Table of Contents
- Based On The Values In Cells B77:b81
- Table of Contents
- Data Analysis and Interpretation: Insights from Cells B77:B81
- Understanding the Data in Cells B77:B81
- Data Cleaning and Preparation
- Descriptive Statistics
- Inferential Statistics
- Data Visualization
- Interpreting the Results and Drawing Conclusions
- Advanced Analytical Techniques (If Applicable)
- Conclusion
- Latest Posts
- Latest Posts
- Related Post
Data Analysis and Interpretation: Insights from Cells B77:B81
This article delves into the process of data analysis, focusing specifically on a dataset residing within cells B77:B81 of a spreadsheet. While the exact content of these cells remains unknown, this exploration will cover methodologies applicable to various data types encountered in these cells, outlining how to extract meaningful insights and present those findings effectively. We'll cover data cleaning, descriptive statistics, inferential statistics, and visualization techniques crucial for a robust analysis. Remember, the strength of any analysis hinges on the quality of the data and the appropriate application of analytical methods.
Understanding the Data in Cells B77:B81
Before embarking on any analysis, it's crucial to understand the nature of the data contained within cells B77:B81. This understanding forms the foundation for selecting the correct analytical techniques. Key questions to address include:
-
What type of data is present? Is it numerical (continuous or discrete), categorical (nominal or ordinal), or a mixture of types? Numerical data allows for quantitative analysis, while categorical data requires different approaches. Identifying the data type guides the choice of statistical tests and visualizations.
-
What is the meaning of the data? Understanding the context of the data is crucial. What do the values represent? Are they measurements, counts, ratings, or categories? Knowing the context helps in interpreting the results and drawing meaningful conclusions.
-
What is the scale of measurement? This is closely tied to the data type. Numerical data can be measured on different scales (e.g., ratio, interval, ordinal). The scale of measurement impacts the statistical methods that can be applied. For instance, calculating a mean is appropriate for ratio data but not necessarily for ordinal data.
-
Are there any missing values? Missing data is a common problem in real-world datasets. Understanding the extent and nature of missing data is crucial for proper analysis. Techniques like imputation or exclusion might be necessary to handle missing values.
-
Are there any outliers? Outliers are data points that significantly deviate from the rest of the data. Outliers can skew the results of statistical analysis and should be investigated carefully.
Data Cleaning and Preparation
Once the nature of the data is understood, the next step is data cleaning. This involves identifying and handling errors, inconsistencies, and missing values. Data cleaning is crucial for obtaining accurate and reliable results. Common data cleaning techniques include:
-
Handling missing values: Strategies include imputation (replacing missing values with estimated values), exclusion (removing data points with missing values), or employing statistical methods designed for incomplete data. The best approach depends on the extent and nature of the missing data.
-
Identifying and correcting errors: This involves carefully scrutinizing the data for inconsistencies and errors, such as typos, incorrect data entries, or duplicated records. Data validation techniques can be used to flag potential errors for review.
-
Data transformation: Sometimes, data transformation is needed to prepare the data for analysis. This might involve converting data types, standardizing units of measurement, or creating new variables from existing ones. For example, you might transform skewed data using logarithmic or square root transformations.
Descriptive Statistics
After cleaning the data, the next step is to calculate descriptive statistics. These statistics summarize the main features of the data. Key descriptive statistics include:
-
Measures of central tendency: These include the mean (average), median (middle value), and mode (most frequent value). The choice of central tendency measure depends on the data distribution and the presence of outliers.
-
Measures of dispersion: These include the range (difference between the maximum and minimum values), variance, and standard deviation (measures of the spread of the data around the mean). These statistics provide insights into the variability of the data.
-
Skewness and kurtosis: These measures describe the shape of the data distribution. Skewness indicates the asymmetry of the distribution, while kurtosis measures the "peakedness" of the distribution.
-
Frequency distributions and histograms: These are graphical representations of the data distribution, providing a visual summary of the data.
Inferential Statistics
Inferential statistics involves using sample data to make inferences about the population from which the sample was drawn. This may involve hypothesis testing, confidence intervals, or regression analysis, depending on the research question and data type. Inferential statistics allow us to make generalizations about a larger population based on a smaller sample. Examples include:
-
Hypothesis testing: This involves formulating a hypothesis about the population and testing whether the sample data supports the hypothesis. Common statistical tests include t-tests, ANOVA, and chi-squared tests.
-
Confidence intervals: These provide a range of values within which the true population parameter is likely to fall. The width of the confidence interval reflects the uncertainty associated with the estimate.
-
Regression analysis: This technique is used to model the relationship between two or more variables. Linear regression is commonly used to model linear relationships between variables, while other regression techniques can be used for more complex relationships.
Data Visualization
Data visualization is a crucial aspect of data analysis. Visualizing the data can reveal patterns, trends, and outliers that might not be apparent from looking at numerical summaries alone. Effective visualizations help in communicating the findings of the analysis to a wider audience. Common visualization techniques include:
-
Histograms: Used to display the distribution of a single numerical variable.
-
Box plots: Useful for comparing the distribution of a numerical variable across different groups.
-
Scatter plots: Show the relationship between two numerical variables.
-
Bar charts: Used to display the frequency or proportion of different categories.
-
Pie charts: Show the proportion of different categories within a whole.
-
Line charts: Show trends over time or other continuous variables.
Interpreting the Results and Drawing Conclusions
Once the descriptive and inferential analyses are complete, it's time to interpret the results and draw meaningful conclusions. This involves critically examining the findings, considering potential limitations of the analysis, and communicating the results effectively. Key aspects of interpretation include:
-
Contextualizing the findings: The results should be interpreted in the context of the research question and the data's meaning. What do the findings suggest about the phenomenon under investigation?
-
Considering potential limitations: All analyses have limitations. It's crucial to acknowledge these limitations and discuss how they might affect the interpretation of the results. This might include limitations related to the sample size, the data quality, or the analytical methods used.
-
Communicating the results effectively: The findings should be communicated clearly and concisely, using both numerical summaries and visualizations. The audience should be considered when choosing the method of communication. Reports, presentations, or visualizations may be appropriate depending on the audience and the complexity of the analysis.
Advanced Analytical Techniques (If Applicable)
Depending on the nature and complexity of the data in cells B77:B81, more advanced analytical techniques may be appropriate. These might include:
-
Time series analysis: If the data represents a time series (e.g., stock prices, temperature readings), time series analysis techniques can be used to identify trends, seasonality, and other patterns in the data.
-
Clustering: If the data represents observations with multiple attributes, clustering techniques can be used to group similar observations together.
-
Classification: If the goal is to predict a categorical outcome based on other variables, classification techniques such as logistic regression or decision trees can be used.
-
Machine learning techniques: More advanced machine learning algorithms can be applied to discover patterns, make predictions, or identify anomalies in complex datasets.
Conclusion
Analyzing the data in cells B77:B81 requires a systematic approach that begins with understanding the data's nature and progresses through data cleaning, descriptive and inferential statistics, and effective data visualization. The choice of analytical techniques depends on the data type, research questions, and the desired level of detail in the analysis. Remember, robust data analysis is a multi-step process that demands careful consideration at each stage, from data preparation to result interpretation and communication. The ultimate goal is to extract meaningful insights from the data, helping to inform decision-making and improve understanding. The specific methods applied will ultimately depend on the actual data found in those cells, but the principles outlined here offer a comprehensive framework for effective data analysis, irrespective of the content.
Latest Posts
Latest Posts
-
How Many Kg Is 155 Pounds
May 19, 2025
-
How Many Ml In A 26
May 19, 2025
-
How Many Kilos Is 125 Pounds
May 19, 2025
-
How Many Weeks Is 120 Days
May 19, 2025
-
How Tall Is 56 Inches In Feet
May 19, 2025
Related Post
Thank you for visiting our website which covers about Based On The Values In Cells B77:b81 . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.